http_cache_store_memory
=====
`http_cache_store_memory` is an in-memory LRU cache that can be used as a backend for `http_cache`.
It implements the `http_cache_store` behaviour.
It supports:
- in-memory caching, with fixed limit or limit in % of used system memory
- clustering, using BEAM distribution. The following events are broadcast:
- newly cached HTTP responses (in an efficient manner)
- invalidation requests
- warmup: already present nodes send their most recently used cached HTTP responses to joining nodes
- telemetry events (see [Telemetry](#telemetry))
- Backpressure mechanisms to avoid overloading the whole system with caching operations
- the optional `http_cache_store:invalidate_by_alternate_key/1` callback
It uses Erlang's capabilities and doesn't require external stores (Redis, memcached, DB...).
Under the hood, it uses ETS tables, system monitor and Erlang's distribution.
For on-disk caching, see: [`http_cache_store_disk`](https://github.com/tanguilp/http_cache_store_disk).
## Support
OTP25+
## Usage
This is an OTP application, and automatically starts.
### Configuration parameters
- `cluster_enabled`: exchange of information between nodes of the Erlang cluster is enabled.
Defaults to `false`
- `memory_limit`: how much memory is allocated for caching. If this is an integer, then it's the
number of bytes allocated to store the cached responses. If it is a float, it's the system memory
threshold that triggers nuking older entries. Defaults to `0.9`, that is, as soon as 90% of the
system memory is used, objects are deleted until system memory use no longer exceeds this threshold
- `max_concurrency`: how many workers are to be working at the same time for adding new cache
entries (including from remote nodes). Defaults to `32`
- `pull_table_stats_interval`: how often stats are retrieved and associated telemetry event emitted,
in milliseconds. Defaults to `1000`
- `warmup_nb_objects`: how many objects are sent to joining nodes when they request warm-up.
Default to `5000`
- `warmup_timeout`: how long the warmup process is active, that is it tries to get objects from
joining nodes, in milliseconds. Default to `20000`
- `limit_check_interval`: how often to check for limits, and trigger LRU nuking when exceeded, in
milliseconds. Defaults to `200`
- `expired_resp_sweep_interval`: how often expired responses are purged, in milliseconds.
Defaults to `3000`
- `outdated_lru_sweep_interval`: how often outdated LRU entries are purged, in milliseconds.
Defaults to `2000`
All are environment parameters.
All are read at runtime (and can be changed dynamically) except `cluster_enabled`.
## Installation
Erlang (rebar3):
```erlang
{deps, [{http_cache_store_memory, "~> 0.3.0"}]}.
```
Elixir:
```elixir
{:http_cache_store_memory, "~> 0.3.0"}
```
## Telemetry
- `[http_cache_store_memory, object_deleted]` is emitted whenever an object is deleted
- Measurements: none
- Metadata:
- `reason`: one of `lru_nuked`, `expired`, `url_invalidation`, `alternate_key_invalidation`
- `[http_cache_store_memory, memory]` is emitted regularly by the stats service
- Measurements:
- `total_mem`: total memory used by `http_cache_store_memory` subsystems
- `objects_mem`: memory used by `http_cache_store_memory` to store HTTP responses
- `lru_mem`: memory used by `http_cache_store_memory` to store LRU data
- `objects_count`: number of HTTP responses cached
- Metadata: none
- `[http_cache_store_memory, lru_nuker]`: events triggered by the LRU nuker process
(uses `telemetry:span/3`)
- `[http_cache_store_memory, expired_lru_entry_sweeper]`: events triggered by the LRU sweeper process
(uses `telemetry:span/3`)
- `[http_cache_store_memory, expired_resp_sweeper]`: events triggered by the outdated response
sweeper process (uses `telemetry:span/3`)
## Architecture
This application uses 3 ETS tables:
- the object table, that stores the cached HTTP responses
- the LRU table, that stores the last time a response was used (returned to a client)
- the configuration table
The configuration table is used to store when the limit is reached, so as to discard immediately
requests to cache HTTP responses.
The object and LRU tables store the following tuples:
Object table: `{ObjectKey, VaryHeaders, UrlDigest, Response, RespMetadata, Expires, SeqNumber}`
LRU table: `{{LastUsedTime, ObjectKey, SeqNumber}}`. Note there's only one 3-tuple entry.
Both are `ordered_set` tables, so that:
- they can be traversed even though they're modified at the same time. This is useful for cleanup
processes (see below)
- oldest entries of the LRU table can be found very efficiently (since the timestamp is the primary
key, the entry returned by `ets:first/1` is the oldest)
Also note that the `ObjectKey` of the object table is a `{RequestKey, VaryHeadersHash}` tuple.
Indeed, the same URL and HTTP verb can have different HTTP responses, depending on the `vary` header
and we need to return all of them to `http_cache` to select the correct one. Fortunately, matching
on the first term of a compound key in an `ordered_set` table is very efficient.
Whenever `http_cache:notify_response_used/2` is called, a new entry is added in the LRU table
with the current time, object key and a `SeqNumber`. This sequence number is a random integer and
is also updated in the object table along with the cached HTTP response. When nuking older entries,
we then can use this sequence number to determine if the cached response was used since
(the `SeqNumber` between the 2 tables don't match) or not (they do match).
At startup, some processes are launched:
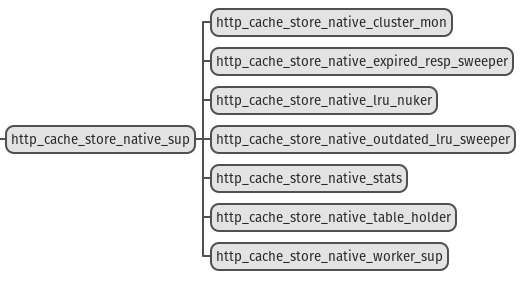
`http_cache_store_memory_table_holder` holds the ETS tables.
`http_cache_store_memory_worker_sup` is a supervisor responsible for spawning workers that
insert or update new HTTP responses into the ETS object table, invalidate entries, and process
cluster work. It is used for backpressure, as there's a maximum number of tasks that can be run at
the same time (except for invalidation requests).
`http_cache_store_memory_stats` collects stats about memory, emits telemetry events related to
it and provides with helper function to calculate how much allocated memory is used, depending on
the configuration.
`http_cache_store_memory_cluster_mon` handles communication with the other members of the cluster,
by:
- broadcasting and handling invalidation requests
- listening for new cached objects available from other members, and requesting them if they're
missing locally
- sending warmup request on startup.
Then we have 3 sweeper processes:
- `http_cache_store_memory_expired_resp_sweeper` removes HTTP responses than can no longer be used,
that is those whose grace period have expired
- `http_cache_store_memory_lru_nuker` starts nuking least recently used HTTP responses as soon
as 99% of the allocated memory for caching is used. It does it more and more aggressively by first
nuking 200 objects, then 400, then 800... until this threshold is no longer exceeded. It also blocks
any new insert of HTTP responses as soon as the threshold exceeds 100%
- `http_cache_store_memory_outdated_lru_sweeper` is responsible for sweeping LRU entries that no
longer have a corresponding HTTP response in the object table. That might happen for 2 reasons:
- a newer LRU entry was inserted since, that is the response was returned to a client and
`http_cache:notify_response_used/2` was called
- the HTTP response was replaced with a freshest one