# xb5
[](https://github.com/g-andrade/xb5/actions/workflows/ci.yml)
[](https://www.erlang.org)
[](https://hex.pm/packages/xb5)
[](https://hexdocs.pm/xb5/)
[](https://github.com/g-andrade/xb5/commits/main)
`xb5` is an Erlang library providing
[B-tree](https://en.wikipedia.org/wiki/B-tree) (order 5) alternatives to OTP's
`gb_trees` and `gb_sets`.
Benchmarks show **[1.2–2.5× faster](#benchmarks)** execution and equal or lower
heap usage for most operations.
It provides three modules:
* **`xb5_bag`** — ordered
[multiset](https://en.wikipedia.org/wiki/Set_(abstract_data_type)#Multiset)
with [order-statistic](https://en.wikipedia.org/wiki/Order_statistic_tree)
O(log n) operations (rank, nth element, percentile)
* **`xb5_sets`** — ordered set, drop-in alternative to
[`gb_sets`](https://www.erlang.org/doc/apps/stdlib/gb_sets.html)
* **`xb5_trees`** — ordered key-value store, drop-in alternative to
[`gb_trees`](https://www.erlang.org/doc/apps/stdlib/gb_trees.html)
## Installation
Available on [Hex](https://hex.pm/packages/xb5) · [API docs](https://hexdocs.pm/xb5/)
`rebar.config`:
```erlang
{deps, [
% [...]
{xb5, "~> 1.0"}
]}
```
`your_application.app.src`:
```erlang
{applications, [
kernel,
stdlib,
% [...]
xb5
]}
```
For Elixir, [`xb5_elixir`](https://hexdocs.pm/xb5_elixir/) provides an
idiomatic wrapper.
## Usage
### xb5_bag
An ordered multiset, allowing multiple occurrences of the same value. Supports
order-statistic operations such as `percentile/3` and `percentile_bracket/3`.
`push/2` always inserts a new copy; `add/2` is idempotent.
```erlang
> B0 = xb5_bag:new().
> B1 = xb5_bag:push(x, B0).
> B2 = xb5_bag:push(x, B1).
> xb5_bag:size(B2).
2
> xb5_bag:count(x, B2).
2
> xb5_bag:to_list(xb5_bag:add(x, B2)).
[x, x]
```
Order statistics on numerical data:
```erlang
> L = xb5_bag:from_list([12, 14, 14, 15, 15, 18, 20, 25, 30, 100]).
> xb5_bag:count(15, L).
2
> xb5_bag:nth(1, L).
12
> xb5_bag:nth(5, L).
15
> xb5_bag:nth(10, L).
100
> xb5_bag:percentile_bracket(0.0, L).
{exact, 12}
> xb5_bag:percentile_bracket(0.5, L).
{between, 15, 18, 0.5}
> xb5_bag:percentile(0.5, L).
{value, 16.5}
> xb5_bag:percentile(0.75, L).
{value, 23.75}
```
`percentile_bracket/2` returns `{exact, X}` when the percentile falls exactly on
an element, or `{between, Low, High, T}` when between two — where `T` is the
linear interpolation weight. The default method is `inclusive` (equivalent to
Excel [`PERCENTILE.INC`](https://support.microsoft.com/en-au/office/percentile-inc-function-680f9539-45eb-410b-9a5e-c1355e5fe2ed));
`exclusive` and `nearest_rank` are also available via `percentile_bracket/3`.
`percentile/2` performs the interpolation and returns `{value, Result}`.
### xb5_sets
Ordered set, drop-in alternative to
[`gb_sets`](https://www.erlang.org/doc/apps/stdlib/gb_sets.html).
```erlang
> S = xb5_sets:from_list([3, 1, 2, 1]).
> xb5_sets:to_list(S).
[1, 2, 3]
> xb5_sets:is_member(2, S).
true
> xb5_sets:smallest(S).
1
> xb5_sets:largest(S).
3
> xb5_sets:smaller(2, S).
{found, 1}
> xb5_sets:larger(2, S).
{found, 3}
```
```erlang
> A = xb5_sets:from_list([1, 2, 3, 4, 5]).
> B = xb5_sets:from_list([3, 4, 5, 6, 7]).
> xb5_sets:to_list(xb5_sets:union(A, B)).
[1, 2, 3, 4, 5, 6, 7]
> xb5_sets:to_list(xb5_sets:difference(A, B)).
[1, 2]
> xb5_sets:to_list(xb5_sets:intersection(A, B)).
[3, 4, 5]
```
### xb5_trees
Ordered key-value store, drop-in alternative to
[`gb_trees`](https://www.erlang.org/doc/apps/stdlib/gb_trees.html).
```erlang
> T = xb5_trees:from_list([{a, 1}, {b, 2}, {c, 3}]).
> xb5_trees:get(a, T).
1
> xb5_trees:lookup(d, T).
none
> xb5_trees:smallest(T).
{a, 1}
> xb5_trees:largest(T).
{c, 3}
> xb5_trees:keys(xb5_trees:insert(d, 4, T)).
[a, b, c, d]
> xb5_trees:smaller(c, T).
{b, 2}
> xb5_trees:larger(b, T).
{c, 3}
```
## Benchmarks
[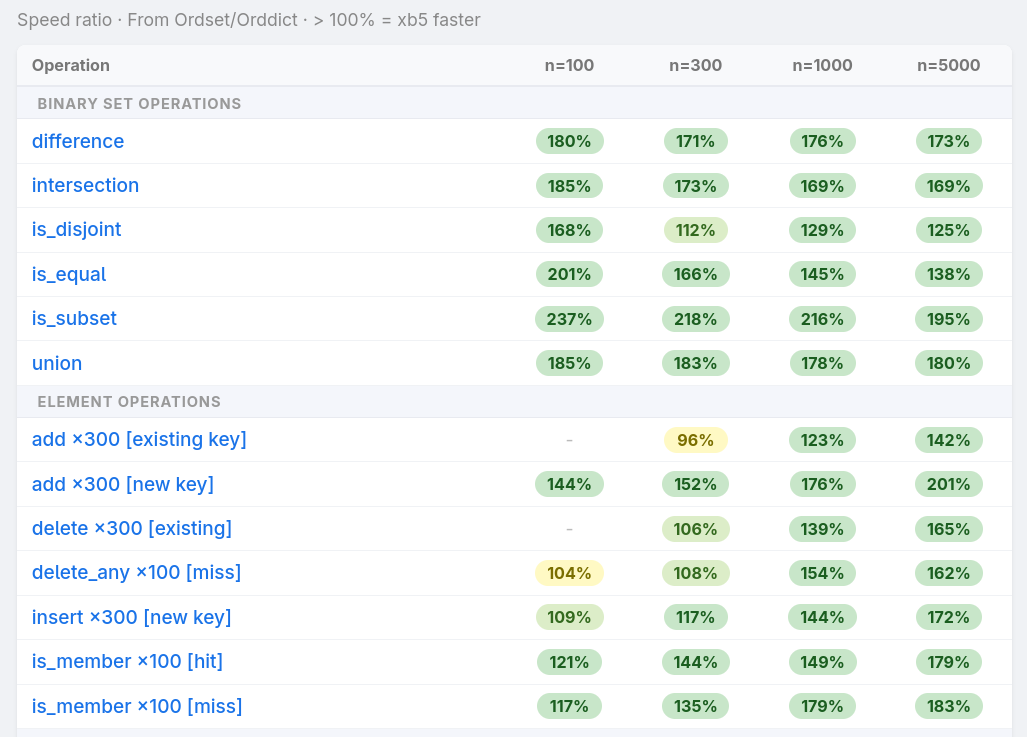](https://www.gandrade.net/xb5_benchmark/report_amd_ryzen7_5700g.html)
[Benchmarks](https://www.gandrade.net/xb5_benchmark/report_amd_ryzen7_5700g.html)
compare all three modules against `gb_sets`/`gb_trees` across 50+ operations
and collection sizes up to 15,000 elements, measuring both runtime and heap
allocation. [All tests](https://github.com/g-andrade/xb5_benchmark) used small
integers (immediate values) as keys. Each module is tested under three build
scenarios: bulk construction from a sorted input, sequential single-key
insertion, and random insertion order. Tests ran on OTP 28 with JIT enabled on
two machines: [AMD Ryzen 7
5700G](https://www.gandrade.net/xb5_benchmark/report_amd_ryzen7_5700g.html) and
[Intel
i5-3550](https://www.gandrade.net/xb5_benchmark/report_intel_i5_3550.html).
In general, measured performance gains grew with collection size.
**`xb5_sets` vs `gb_sets`:**
* Mutations, membership tests, set-algebraic operations (difference, union,
intersection, `is_disjoint`, `is_subset`): **1.2–2.2× as fast**, with similar heap use
* Filter, filtermap, map: **~1.5–2.5× as fast**, with up to ~40% less heap
* Bulk construction: similar or faster speed, **~15–65% less heap**
* Alternating take-smallest/insert-largest: **~2–4× as fast** depending on build scenario
* `is_equal` with no key overlap: **40–126× as fast** — `gb_sets` converts both
sets to lists for the comparison; with identical keys the results are roughly equal
* Iteration: **~25% slower** on the AMD machine; near-equal on the i5
**`xb5_trees` vs `gb_trees`:**
* Lookups: **1.1–1.9× as fast**, with equal heap
* Mutations (insert, update, delete, take): **1.2–1.7× as fast**
* map, keys, values: **1.9–2.5× as fast**; map uses ~47% less heap
* Alternating take-smallest/insert-largest: **1.7–3.3× as fast**
* `take_smallest` and `take_largest`: **14–27% slower** in most build scenarios
**`xb5_bag` vs `gb_sets`:**
* Runtime profile broadly matches `xb5_sets`
* Filter/map operations: up to **~40% less heap**
* Bulk construction: **~15–62% less heap**
* Mutations: **~20–40% more heap**
## Technical Details
### Key density
In a B-tree of order 5, each non-root node holds between 2 and 4 keys.
The average number of keys per node — the *key density* — turns out to be
an important factor for performance.
Early benchmarks showed that:
* When key density drops towards **2**, the tree becomes taller with more
nodes, increasing the cost of traversals.
* When it rises towards **4**, nodes are nearly full, leaving little room
to absorb insertions without splitting. This leads to more frequent
node reallocations and rotations.
* The sweet spot hovers around **3 keys per node**, balancing tree height
against structural churn.
Much of `xb5`'s design follows from keeping key density close to that
sweet spot.
Measured key densities for 1000-element sets:
| Build type | Key density |
|:---|:---:|
| Bulk construction or sequential ops | ~3.0 |
| Random insertions | ~2.9 |
| After heavy random deletion | ~2.6 |
| Adversarial deletion (every 5th element) | ~2.4 |
### Insertion: spilling before splitting
In a textbook B-tree, when a node overflows (5 keys in an order-5 tree),
it splits into two nodes of 2 keys each, pushing the median up. Sequential
insertions cause frequent splits, leaving most nodes half full — a key
density of ~2.
`xb5` adds a step before splitting: if the overflowing node's left sibling
has only 2 keys, the excess key is *spilled* into that sibling instead.
If the node has no left sibling (i.e., it is the leftmost child), the right
sibling is checked. A split only happens when no adjacent sibling can
absorb the extra key (i.e., it already has 3 or more keys). This keeps
nodes fuller and key density close to 3.
### Deletion: reactive rebalancing
[Textbook B-tree deletion](https://www.geeksforgeeks.org/dsa/delete-operation-in-b-tree/)
uses a *proactive* strategy: before descending into a child, ensure it has
more than the minimum number of keys by rotating from a sibling or merging.
This guarantees a single top-down pass with no backtracking, which makes
sense when nodes are mutable and pre-allocated.
In the BEAM, however, all traversed tuples are reallocated on the way
back up regardless — there is no mutation to avoid. `xb5` therefore uses
a *reactive* approach: it descends freely, allowing a child node to
temporarily hold only 1 key after a deletion, and then checks on the way
back up whether a rotation or merge is needed. This was measured to
perform better, as the proactive key movements are often unnecessary and
amount to wasted reallocations.
Additionally, when rebalancing after a deletion, only the left sibling is
checked for a possible rotation (unless the child is the leftmost, in which
case the right sibling is checked). This leads to more frequent merges
compared to the textbook approach of checking both siblings — which both
helps key density and reduces allocations (a merge requires only 1 tuple
allocation, while a rotation requires 3).
### Trade-off: code verbosity
The node modules (`xb5_sets_node`, `xb5_trees_node`, `xb5_bag_node`) are
large and repetitive. This is a deliberate trade-off.
Nodes are not generic tuples accessed via `element`/`setelement` — each
node size has its own explicit tuple layout, packed and unpacked through
macros:
```erlang
-define(LEAF2(E1, E2), {E1, E2}).
-define(LEAF3(E1, E2, E3), {E1, E2, E3}).
-define(LEAF4(E1, E2, E3, E4), {leaf4, E1, E2, E3, E4}).
-define(INTERNAL2(E1, E2, C1, C2, C3), {internal2, E1, E2, C1, C2, C3}).
-define(INTERNAL3(E1, E2, E3, C1, C2, C3, C4), {E1, E2, E3, C1, C2, C3, C4}).
-define(INTERNAL4(E1, E2, E3, E4, C1, C2, C3, C4, C5), {E1, E2, E3, E4, C1, C2, C3, C4, C5}).
```
This explicit pattern matching and tuple construction was necessary to
achieve meaningful performance benefits over `gb_trees`/`gb_sets`.
The code also relies heavily on inlining (`-compile({inline, [...]})`) to
keep things both readable and fast: each operation branches across multiple
node sizes, and dispatching the contents of a node through function calls
would mean passing many arguments. Inlining allows separation of concerns
without paying for the dispatch.
The cost is visible in compiled module sizes — the node modules are
significantly larger than their stdlib counterparts:
| Module | .beam size |
|:---|:---:|
| `gb_sets` | 34K |
| `gb_trees` | 22K |
| `xb5_sets_node` | 96K |
| `xb5_trees_node` | 136K |
| `xb5_bag_node` | 128K |
## License
MIT License
Copyright (c) 2025-2026 Guilherme Andrade
Permission is hereby granted, free of charge, to any person obtaining a
copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be included
in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
